2020-10 upd: we reached the first fundraising goal and rented a server in Hetzner for development! Thank you for donating !
Attention! I apologize for the automatic translation of this text. You can improve it by sending me a more correct version of the text or fix html pages via GITHUB repository.
Deploy Kubernetes cluster on FreeBSD/bhyve (CBSD)
Introduction
Recently, at my new job, my colleagues and I noted a non-standard success story - in our company we completely got rid of the docker (more than two hundred containers - a little, but there was something). Yes! yes! Although this trend has been going on for ten years, the de-dockerization process has brought a lot of joy and relief. Although temporarily ;-)
I will not talk about the pros and cons of docker - I will only remind the well-known truth - there is nothing perfect, and not always the tool or implementation of the solution is most suitable for you. In addition, in the field of IT there is no single right way - there are always options, so our area is fascinating. At some point, inside our company, it came to an understanding that the docker is being used incorrectly and brings more problems than it solves them. To fix this, the IT department received the task of transferring all business processes to the rails of microservice architecture. For this, developers must take into account the specifics and characteristics of the container approach. These questions are beyond the scope of the article, but I can only say that the new concept and the steps taken imply for us the use of containers on an even larger scale (when our applications are really ready for this), in connection with this, the question was raised regarding orchestration by a large number of containers
There are quite a few solutions for container orchestration, but the most popular (or the most famous and highly advertised, is probably, a Kubernetes) Since I plan to conduct many experiments with installing and configuring k8s, I need a laboratory in which I can quickly and easily deploy a cluster in any quantities for myself. In my work and everyday life I use two OS very tightly - Linux and FreeBSD OS. Kubernetes and docker are Linux-centric projects, and at first glance, you should not expect any useful participation and help from FreeBSD here. As the saying goes, an elephant can be made out of a fly, but it will no longer fly. However, two tempting things come to mind - this is very good integration and work in the FreeBSD ZFS file system, from which it would be nice to use the snapshot mechanism, COW and reliability. And the second is the bhyve hypervisor, because we still need the docker and k8s loader in the form of the Linux kernel. Thus, we need to connect a certain number of actions in various ways, most of which are related to starting and pre-configuring virtual machines. This is typical of both a Linux-based server and FreeBSD. What exactly will work under the hood to run virtual machines does not play a big role. And if so - let's take a FreeBSD here!
In my free time, I am a member of CBSD, a project that can provide end users with a more user-friendly interface for managing containers and virtual machines on the FreeBSD platform. Another part of users knows that CBSD is a framework that, thanks to the API, integrates very easily into any of your own scripts to automatically manage the virtual infrastructure, realizing most of the operations at a low level when working with virtual machines. Thus, our task is to build some kind of bridge between operations on the k8s cluster and tasks related to deploying virtual machines. This work took me about 4 hours and turned into a working k8s CBSD module, which is publicly available (starting with the next CBSD version 12.1.5), like everything else related to the CBSD project.
So let's see what we got!
Spoiler: if you prefer to watch the video, a small demo on YouTube (subtitles for English): https://youtu.be/ADBuUCtOF1w
What we have
My goal is to create a small local laboratory with a working k8s cluster, and I have a server at my disposal with the following characteristics:
- 1x3 TB hard drive with FreeBSD 13-CURRENT ( ZFS-on-root )
- RAM: 256 GB
- CPU: Intel(R) Xeon(R) CPU E5-2680 v4 @ 2.40GHz (56 core)
In other words, we have no shortage of resources. Using the Ubuntu 18 cloud image, I generated a kubernetes cloud image, which differs from the Ubuntu image only in that it is connected to the kubernetes repository, and the apt install kubeadm command was executed, so when deploying the image, you can immediately start working with the kubectl utility.
I uploaded the experimental k8s image to the mirrors of the CBSD project. You can start the virtual machine from this image through the standard CBSD dialog and the bconstruct-tui command:
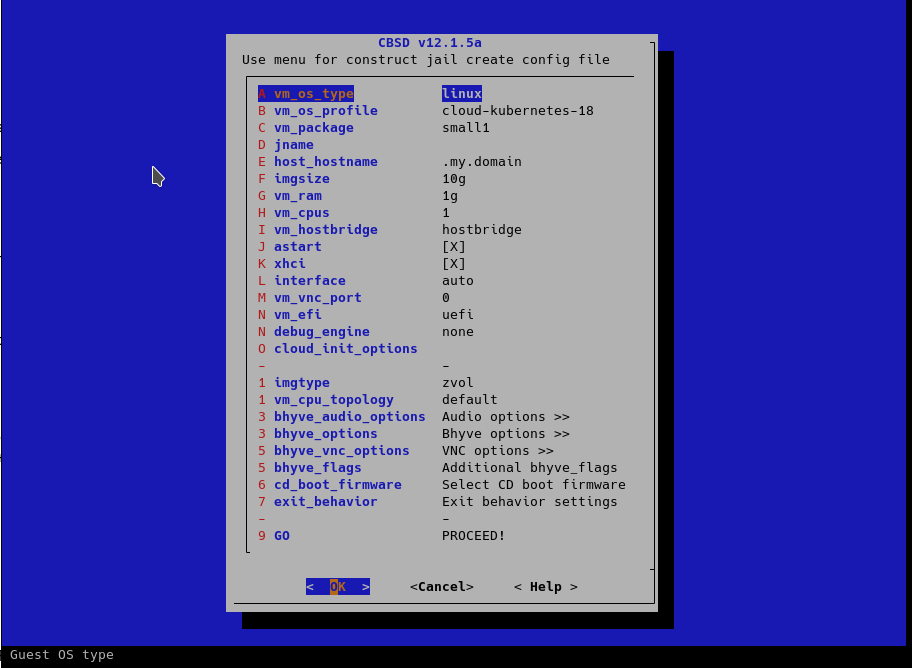
First of all, we need to choose the type of guest - in the case of k8s, our guest is Linux:
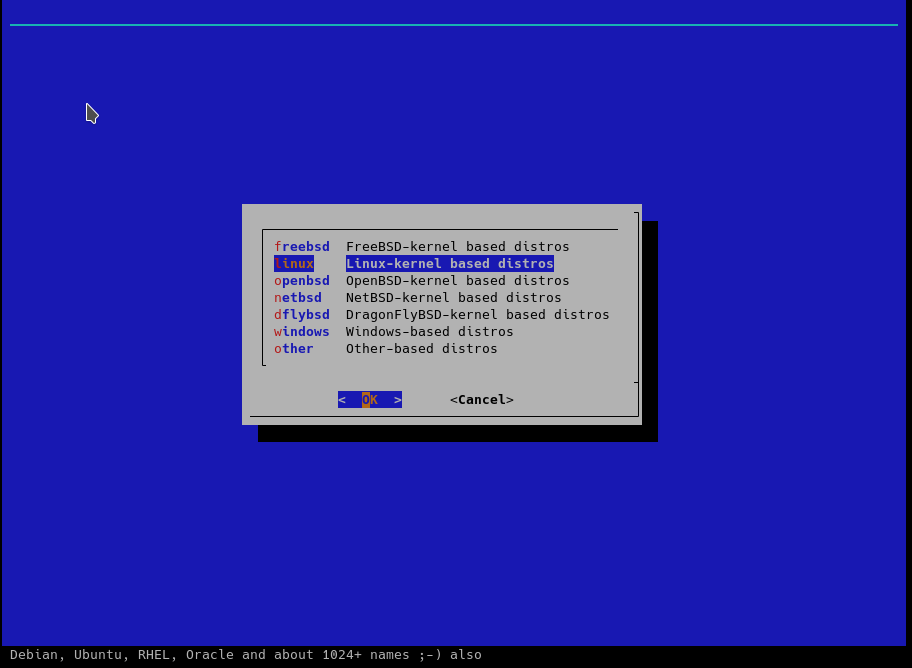
Next, select the name containing kubernetes, in the list of ready-made Linux profiles - this is a cloud image, so look for it at the bottom of the list:

Edit the remaining parameters, if necessary:
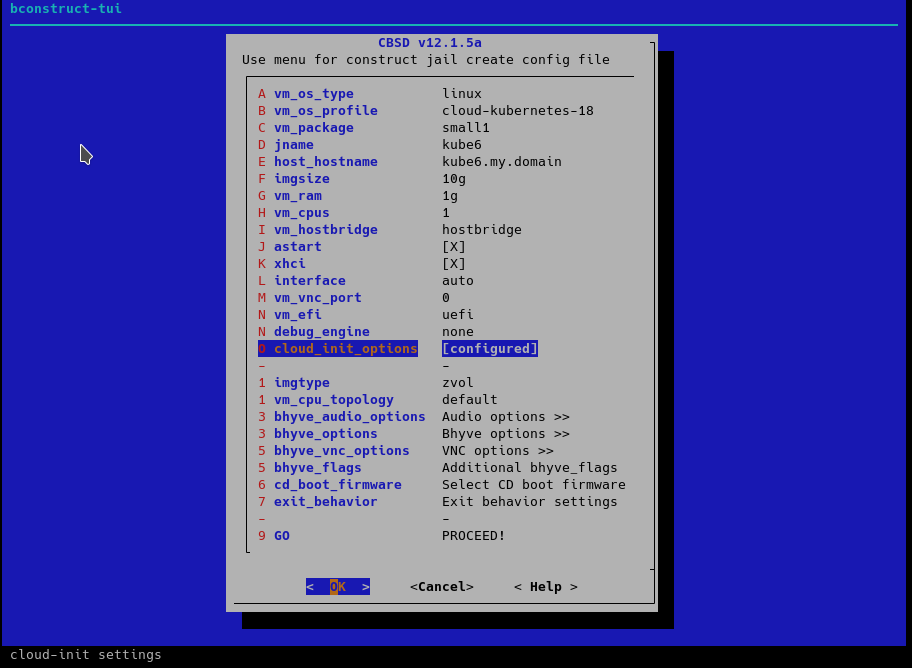
For example, we can change the network settings for the cloud-init helper:
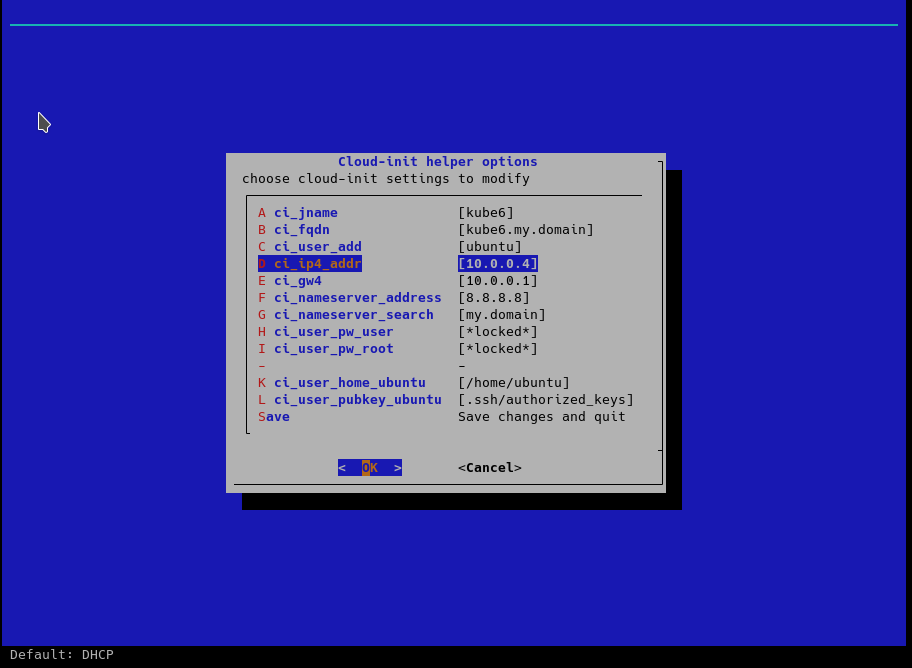
After editing the parameters, we create a virtual machine:
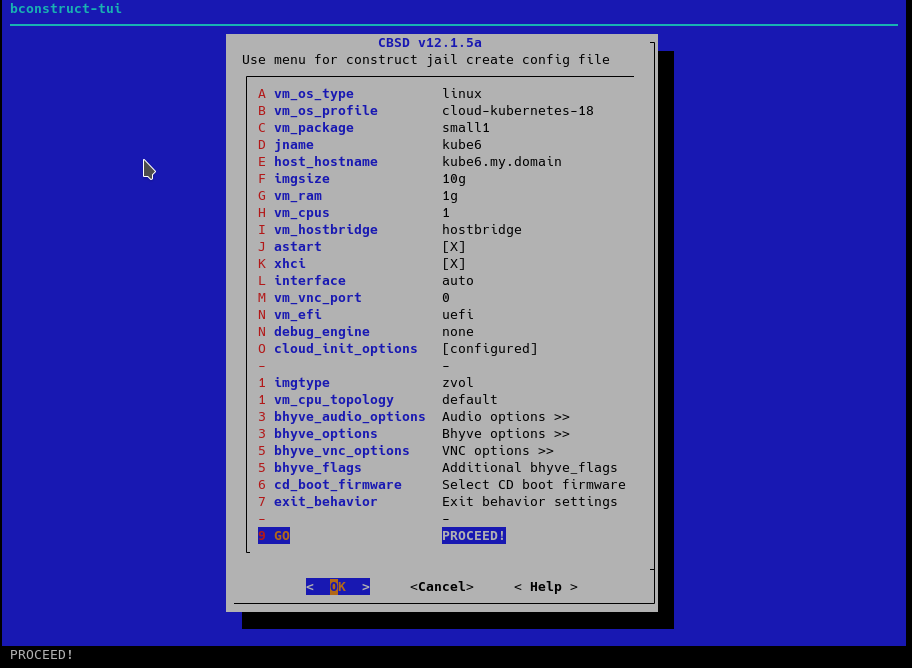
As a result, we got a working virtual machine in which kubernetes is already installed, but this is where the main features of CBSD for kubernetes end - it focuses on other tasks.
However, this is already good - thanks to cloud-init, you do not need to install the OS every time using the installer, and you do not need to install kubernetes every time after installing the OS - you just need to start the VM from the gold image. If you like to do manual work in some cases - 20 seconds of starting the virtual machine - and you can continue.
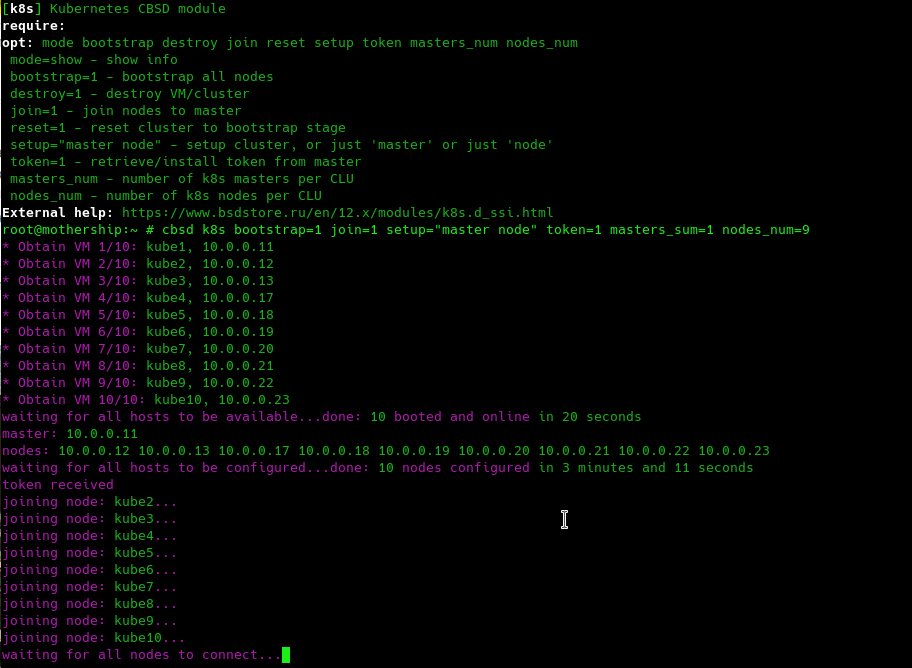
Since creating and configuring k8s is also not a trivial task (primarily because it is a lot of monotonous monkey work in the form of repeating a large number of identical commands), I placed these commands in separate scripts and these scripts have received the status k8s module for CBSD, where all operations of which begin with a prefix with the same name k8s. All CBSD commands display information about their required or not-so arguments with a brief description through the --help argument. The module offers a small number of operations, including bootstrap, join, configuring and receiving a Kubernetes token. You can start these operations in strict order one after another, or you can specify all the necessary arguments one time - the module itself will figure out when and what to do. For example, when you execute this command:
cbsd k8s bootstrap=1 join=1 token=1 setup="master node"we ask the module to complete the entire cycle of initializing one cluster, with the export of the token for working with kubectl using the CLI through a remote machine:
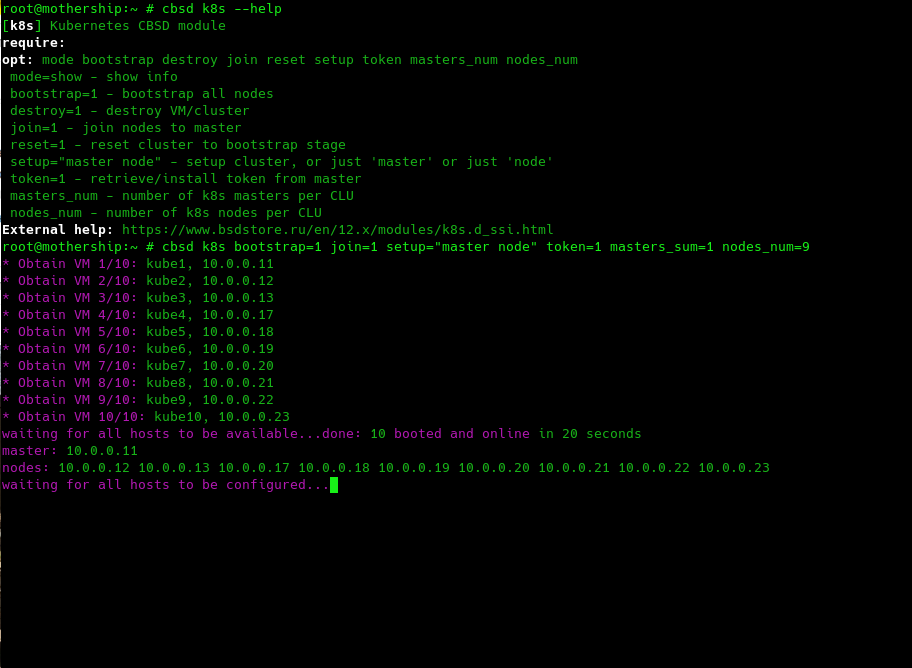
The CBSD module performs its work in various places - in parallel, in some - sequentially.
For example, each script is executed in parallel, but before the module can proceed to the next step, it needs to make sure that the most recent or slowest node has completed the configuration and is ready for the next step. Thus, the final step of each individual scenario is expectation. For example, we can observe the fact of parallelization and the progress of internal tasks in the output of cbsd taskls:
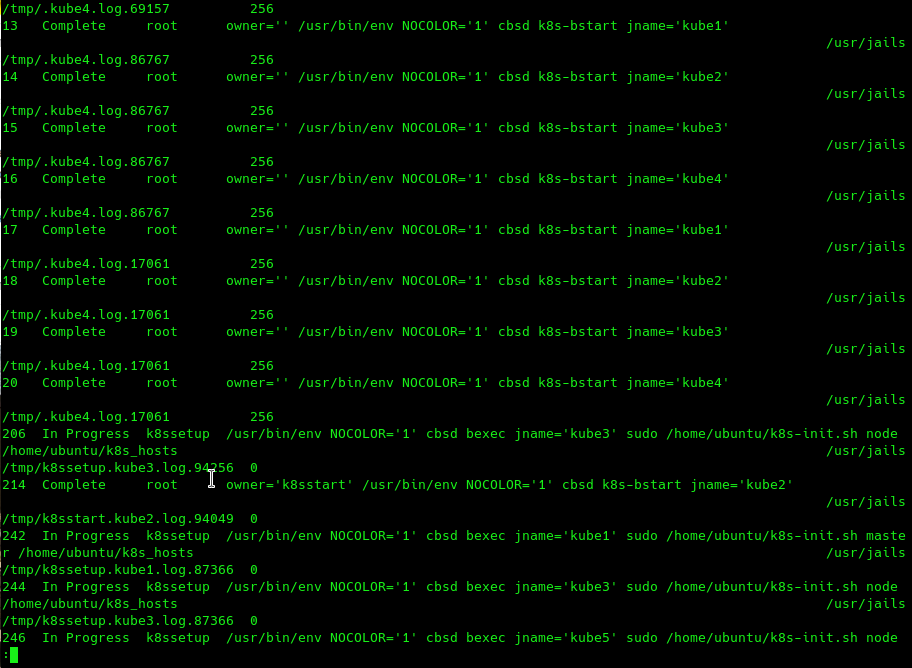
Sooner or later (in my case - within 20 seconds), the module switched from the initial boot to the configuration phase, when one node is assigned the 'master' role, all the others become 'worker. The purpose of k8s bootstrap is to start a virtual machine with kubernetes from a golden image - which we did above through cbsd bconstruct-tui by starting one virtual machine from the dialog interface. Thus, within 20 seconds we started 10 virtual machines, and now we can observe them through the output of cbsd bls:
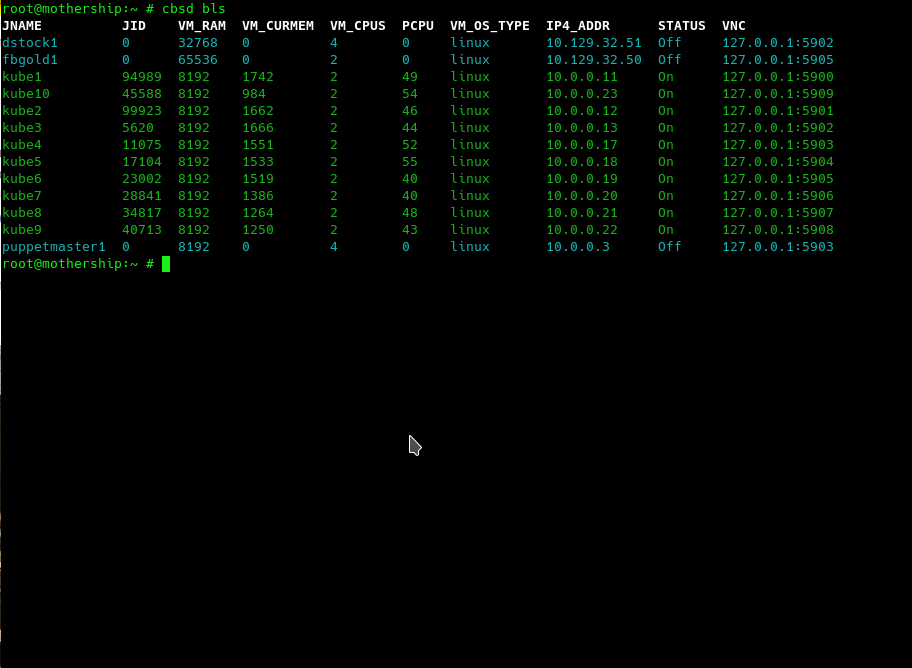
I must say that the role of CBSD here is not only launching virtual machines and working with cloud-init, but also automatically searching for free names for new containers (in this case, the kube mask is used as the beginning of the container name) and searching and automatically assigning free IPs addresses that the system takes from the CBSD node ip pool settings. The screenshot shows that the IP addresses 10.0.0.XX that are issued to virtual machines do not always go sequentially - some of them are already on the network.
The configuration stage for master/worker is the longest and takes 3 minutes:
Then comes the join stage, which takes 42 seconds of our life. Finally, the script, exporting the token, succeeds:
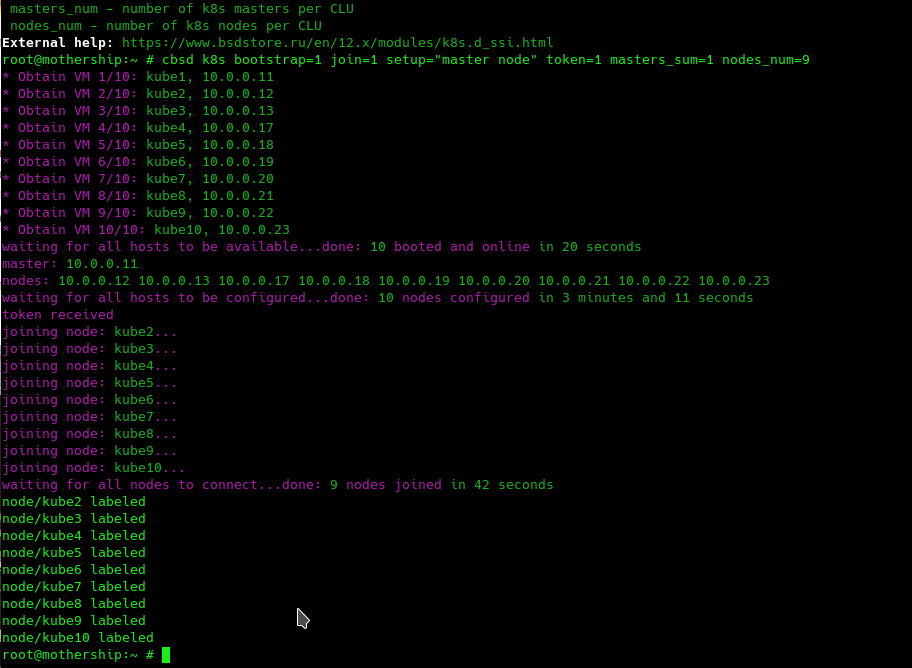
Since we exported (token=1) the token for working with k8s to the local machine, we can work with the cluster directly from the FreeBSD host. We can immediately execute the 'kubectl get nodes' command and make sure everything is in place.
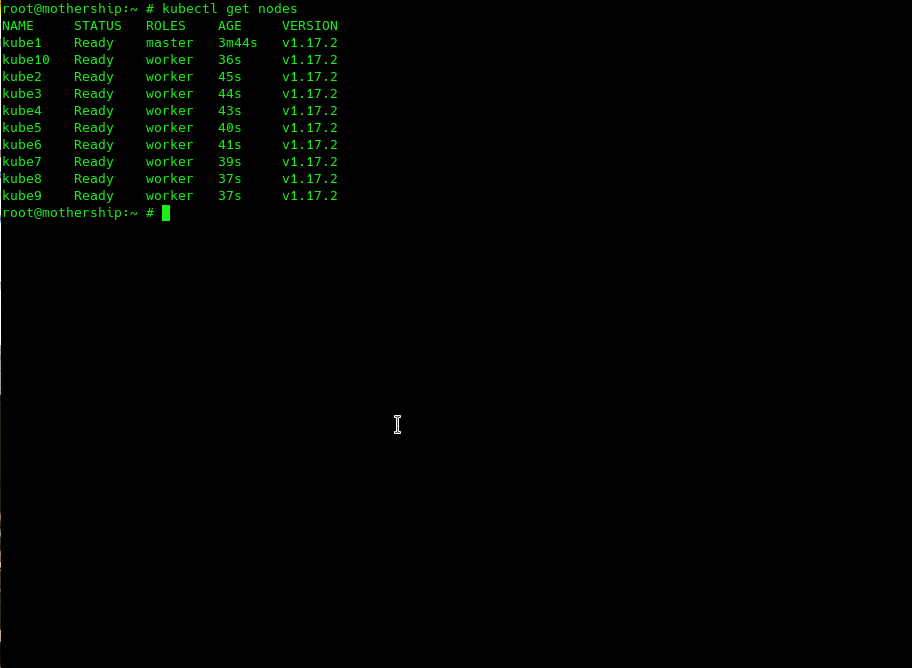
So, the cluster is ready to go. To test, you can apply the sample from the official k8s documentation and run your first container in a new cluster:
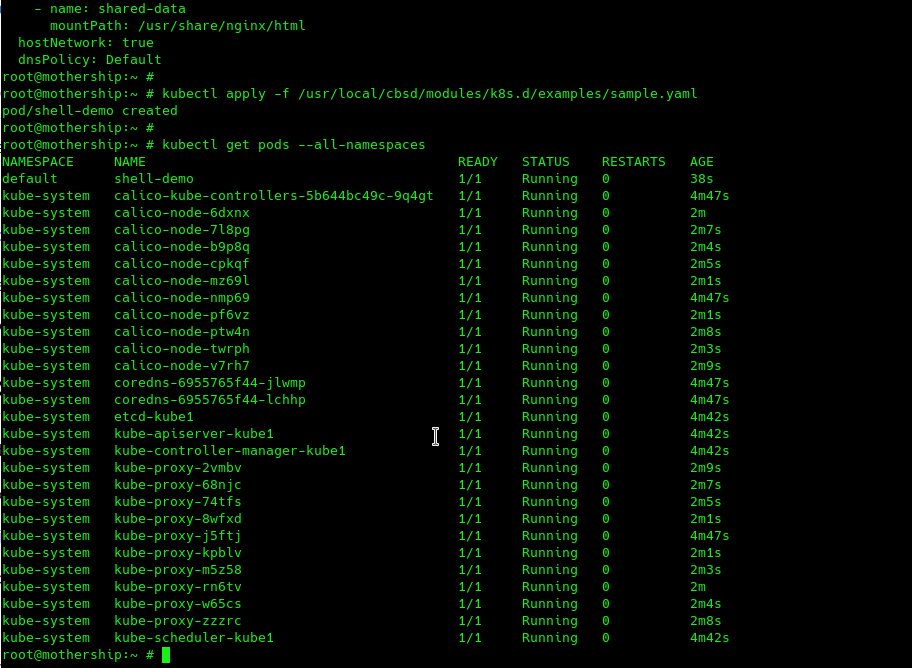
To delete cluster, there is an destroy=1 argument (either delete with the standard cbsd bremove command). Also, you can reset cluster settings without destroying virtual machines (reset=1). Enjoy!
A small podcast with demos of this article on Youtube: https://youtu.be/ADBuUCtOF1w
Conclusions and Future Plans
In the context of a dynamically developing IT industry, it is extremely important to automate all possible operations and get the result as soon as possible - to value your time and nerves. And use these limited and most valuable resources to accomplish your own tasks. This article demonstrates the collaboration of a number of technologies: FreeBSD. Linux, ZFS, cloud-init, bhyve, CBSD which were used for one thing - to raise a ready-to-use Kubernetes cluster of any configuration as quickly as possible.
Obviously, the longest step (configure/setup) can also be optimized here, since this step performs various actions that work with remote resources (wget .yaml configurations for calico, etc.) - this can also be included in the cloud image of kubernetes in the future.
Also, it seems like an interesting idea to be able to combine several physical servers with FreeBSD/CBSD via VXLAN, creating a single L2 segment for all containers. Using the p9fs, Ceph, NFS or S3 object storage here also has the right to exist for organizing a single disk space for containers on different physical nodes.
Also, with proper refinement, we can get a FreeBSD and ZFS-based, some fault tolerance and scalable Kubernetes cluster in the form of a black box, where black box - does not mean 'closed'. Here, we mean as a result a framework that does not require an IT specialist to immerse in FreeBSD, bhyve and CBSD technologies, but we get a universal API for controlling and managing K8S clusters, as a final product.Anyone who is interested in FreeBSD / bhyve + kubernetes and wants to run their own SaaS K8S service on their resources using CBSD - write ideas and comments. It would be interesting to provide the public with a simple and cheap way for these operations.