2020-10 upd: we reached the first fundraising goal and rented a server in Hetzner for development! Thank you for donating !
Bhyve vs jail
Контейнеры против гипервизоров: анатомия виртуализации для самых маленьких
Здесь дан небольшой обзор bhyve(8) и сравнение в подходе виртуализации и контейниризации.
Bhyve - это гипервизор второго типа (на основе базовой ОС), разработан Peter Grehan и Neel Natu в 2010 году и на данный момент, насколько известно, является единственным гипервизором в своем роде, исходный код которого опубликован под максимально либеральной BSD-лицензией (при этом, коммерческих гипервизоров в мире >= 3, GPL-licensed >= 3).
Различия в работе
Контейнер виртуализирует ОС-окружение на уровня ядра, те изоляция одного контейнера/процесса выполняется ядром, обслуживающим всю ОС. Если паникует ядро, падают все контейнеры. Кроме этого, в контейнере нельзя запустить систему, отличную от ОС хоста. Каждый процесс в контейнере представлен для ядра как обычный процесс в системе. Доступ к памяти, процессору и устройствам происходит напрямую. На всем участке кода ядра в ответственных местах присутствуют кейсы на jailed-проверки вида:
if (jailed(cred)) jail_related_area
или
if (prison_check(td, cred) == 0) allow_action_for_jail
Гипервизор же виртуализирует машину полностью. Те, с точки зрения гостя, все ресурсы выглядят как настоящее оборудование. Виртуальная машина и все процессы в ней выглядят для хоста как 1 процесс. Ядра гостей и хоста изолированы друг от друга. Гипервизоры в отличие от контейнеров, позволяют запускать другие ОС внутри виртуальной машины. Чтобы понять тот оверхед, который накладывается гипервизорами, вспомним немного истории из жизни виртуальных систем и какие проблемы при этом возникали и как решались. Виртуализация затрагивает 3 главных компонента - CPU, память и I/O.
CPU
Одна из проблем виртуализации CPU - обезопасить основную систему от выполнения некоторых опасных инструкций, которые могут затрагивать глобальное состояние системы или выполнение некоторых I/O операций, которые в состоянии вызвать крах основной системы.
1) Один из вариантов виртуализировать CPU - это эмуляция CPU. Так работает например QEMU и это крайне медленный способ работы. Тем не менее, на часть небезопасных операций в этом случае может быть установлена заглушка.

2) Direct execution. Способ 2 - предоставить выполнение инструкции гостя на реальном процессоре. Данный метод граздо быстрее первого, но требует binary translation, интерпретации и модификации некоторых опасных инструкций на-лету, что достаточно трудоемко с точки зрения реализации. Тем не менее, подобный метод работал в старых версиях VmWare.
3) Паравиртуализация. Также как метод 2, предоставляет возможность выполнить инструкции гостя на реальном процессоре, однако требует модифицированной версии гостевой системы, что в настоящее время нерелевантно. Тем не менее, такой подход был популярен в старых версиях Xen
4) Аппаратная виртуализация, Intel VT-x или AMD-V (SVM). Представляет из себя 2 режима работы CPU: VMX root mode (режим супервизора) и VMX non-root mode (режим гостя, непривилегированный).
Также как в случае с методами 2 и 3, выполнение инструкций происходит напрямую на реальном процессоре, при этом блокируя нежелательные инструкции средствами самого процессора. Что позволяет разработчикам виртуальных систем заявлять, что гвесты на их гипервизорах работают с такой же скоростью как будучи не в невиртуализированной среде. Что является правдой (и заслуга в этом не гипервизоров, а VT-x архитектуры). При этом все основные задачи гипервизоров сводятся к предоставлению интерфейса по управлению виртуальными машинами и получения статистики, а также вызов соответствующих интрукций для перехода и выхода для конкретного гвеста в/из non-root mode.

Память
Виртуализация памяти также прошла некоторую стадию эволюции, начиная от маппинга областей памяти между VM и физическими страницами
![]()
и механизмом теневых страниц (Shadow pages):
![]()
до аппаратного уровня поддержки, Nested Paging (Intel EPT). Основной принцип работы которой заключается в постоении промежуточной таблицы соответствий для Guest physical и Host physical, с помощью которой MMU в 2 шага транслирует соответствующие страницы.
![]()
I/O, VT-d
Кроме CPU и памяти, требуется виртуализизировать I/O, для того, чтобы немодифицированные ОС были в состоянии запускаться и работать с таким (эмулированным) оборудованием, как:
- SATA контроллеры
- NIC адаптеры
- USB, Serial порты
- VGA адаптером
- Irq контроллерами (LAPIC, IO-APIC)
- Clock (HPET,TSC)
- и тд.
Поскольку устройства требуют физический адрес для DMA, а гостевым ОС недоступны физические страницы, для виртуальных систем созданы паравиртуализированные драйвера для I/O операций: virtio, которые в даный момент являются стандрартом де-факто. Также, для PCI устройств и DMA, существует поддержка на уровне процессора (IOMMU (VT-d)) принцип который также строится в построении таблиц трансляций памяти для DMA между гостевыми адресами и физическими.

Bhyve
Теперь подытожим, какую роль во всем занимает FreeBSD, которая как известно, долго запрягает, но быстро ездит. Гипервизор Bhyve успешно "переждал" ;-) все предшествующие сложные этапы эволюции развития и переписывания гипервизоров и в данный момент, при своей работе использует VT-x, VT-d и virtio-драйвера в гостевых системах, представляя из себя современный гипервизор, работающий по алгоритму:
while (1) {
ioctl (VM_RUN, &vmexit);
switch (vmexit.exit_code) {
case IOPORT_ACCESS
emulate_device(vmexit.ioport)
..
}
Где все самое сложное вынесено на уровень оборудования.
На момент написания статьи, помимо virtio для дисковой подсистемы, реализован AHCI режим. Виртуальные дисковые носители в данный момент могут представлять из себя как файловый образ, так и размещаться на ZFS-томах (zvol). Также, эмулируется Serial консоль и 2 типа PCI шины ввода-вывода: hostbridge и amd_hostbridge (Intel / AMD соответственно).
В ближайшее время, разработчики обещали обеспечить поддержку видео (через Cirrus драйвер) и полноценный запуск гостей без прибегания к помощи внешних загрузчиков.
VirtIO или AHCI
В данной главе приведены результаты выполнения diskinfo(8) с соответствующими показателями для одного и того же диска внутри виртуальной машины, но подключенного в первом варианте через virtio, а во втором - через AHCI.
VirtIO:
Seek times:
Full stroke: 250 iter in 0.020636 sec = 0.083 msec
Half stroke: 250 iter in 0.017950 sec = 0.072 msec
Quarter stroke: 500 iter in 0.033842 sec = 0.068 msec
Short forward: 400 iter in 0.026702 sec = 0.067 msec
Short backward: 400 iter in 0.027631 sec = 0.069 msec
Seq outer: 2048 iter in 0.121300 sec = 0.059 msec
Seq inner: 2048 iter in 0.122890 sec = 0.060 msec
Transfer rates:
outside: 102400 kbytes in 0.071878 sec = 1424636 kbytes/sec
middle: 102400 kbytes in 0.070914 sec = 1444003 kbytes/sec
inside: 102400 kbytes in 0.070714 sec = 1448087 kbytes/sec
AHCI:
Seek times:
Full stroke: 250 iter in 0.023152 sec = 0.093 msec
Half stroke: 250 iter in 0.023843 sec = 0.095 msec
Quarter stroke: 500 iter in 0.042602 sec = 0.085 msec
Short forward: 400 iter in 0.034761 sec = 0.087 msec
Short backward: 400 iter in 0.034904 sec = 0.087 msec
Seq outer: 2048 iter in 0.161184 sec = 0.079 msec
Seq inner: 2048 iter in 0.162722 sec = 0.079 msec
Transfer rates:
outside: 102400 kbytes in 0.094570 sec = 1082796 kbytes/sec
middle: 102400 kbytes in 0.086803 sec = 1179683 kbytes/sec
inside: 102400 kbytes in 0.093864 sec = 1090940 kbytes/sec
Чем меньше seek time, тем лучше (VirtIO демонстрирует лучшие показатели)
Если же нужна разница в попугаях относительно трех последних значений (скорость передачи данных, чем больше - тем лучше), то натравив ministat(1) на эти цифры увидим, что VirtIO и в этом параметре превосходит в скорости AHCI на 6%:
x vrates - VirtIO
+ arates - AHCI
+------------------------------------------------------------------------------------------------+
| + + + x xx |
||______M_____A____________| |__AM_||
+------------------------------------------------------------------------------------------------+
N Min Max Median Avg Stddev
x 3 1424636 1448087 1444003 1438908.7 12528.03
+ 3 1082796 1179683 1090940 1117806.3 53741.256
Difference at 95.0% confidence
-321102 +/- 88441.8
-22.3157% +/- 6.14645%
О настоящем оверхеде.
Теперь мы подошли вплотную в вопросу, которому посвящена статья - есть ли разница в оверхеде, в чем она выражается и что лучше - гипервизоры или контейнеры. И если в теории, разница между контейнерами (минимум оверхеда) и гипервизорами ясна, то на практике это рассчитать и предсказать достаточно сложно.
Относительно процессорных мощностей действительно, инструкции на процессоре выполняются с той же скоростью, как если бы они работали в нативной режиме, поскольку они выполняются напрямую. Однако необходимо иметь ввиду, что при аггресивном I/O (например, постоянная/продолжительная/высокая нагрузка на сеть или на дисковую подсистему) провоцирует гиганское количество переключений/прерываний ( VMEnter/VMExits ) в работе VTx/VTd (фунционал virtio-драйверов тоже не бесплатен) и тем самым, делает виртуализированные системы менее эффективными.
Другими словами стоит ожидать, что чем выше I/O, тем в геометрической прогрессии эффективность гипервизорных систем будет падать.
Для примера, запущенный процесс bhyve, если на него взглянуть из ktrace(1) или dtrace(1), будет генерировать следующий флуд системных вызовов:
22506 vcpu 1 CALL ioctl(0x3,0xc0787601,0x7fffff7fbe40) 22506 vcpu 0 RET ioctl 0 22506 vcpu 0 CALL ioctl(0x3,0xc0787601,0x7fffff9fce40) 22506 vcpu 0 RET ioctl 0 22506 vcpu 0 CALL ioctl(0x3,0xc0787601,0x7fffff9fce40) 22506 vcpu 0 RET ioctl 0 22506 vcpu 0 CALL ioctl(0x3,0xc0787601,0x7fffff9fce40) 22506 vcpu 0 RET ioctl 0 22506 vcpu 0 CALL ioctl(0x3,0xc0787601,0x7fffff9fce40) 22506 vcpu 1 RET ioctl 0 22506 vcpu 0 RET ioctl 0 22506 vcpu 1 CALL ioctl(0x3,0xc0787601,0x7fffff7fbe40) 22506 vcpu 0 CALL ioctl(0x3,0xc0787601,0x7fffff9fce40) 22506 vcpu 1 RET ioctl 0 22506 vcpu 1 CALL ioctl(0x3,0xc0787601,0x7fffff7fbe40) 22506 vcpu 1 RET ioctl 0 22506 vcpu 1 CALL ioctl(0x3,0xc0787601,0x7fffff7fbe40) 22506 vcpu 1 RET ioctl 0 22506 vcpu 1 CALL ioctl(0x3,0xc0787601,0x7fffff7fbe40) 22506 vcpu 1 RET ioctl 0 22506 vcpu 1 CALL ioctl(0x3,0xc0787601,0x7fffff7fbe40)
Из которого сложно сделать какой-то вывод. Но можно для наглядности воспользоваться pmc(3), чтобы посмотреть картину на уровне процессора, ядра и системных вызовов и увидеть работу системы изнутри. Для этого запустим все отличные от VM процессы на другом ядре (в примере, все процессы автора запущены в клетке KDE4, которой установлен cpuset_setaffinity на 3 ядро), а сам bhyve запустим на 2 ядре, чтобы при профилировании нам не попадало ничего лишнего, только bhyve:

% cpuset -c -l 2 cbsd bstart f10 % pmcstat -c 2 -O sys.stat -S instructions
Собрав немного статистики (даже не нагружая систему большим количеством I/O операций), прерываем pmcstat и на выходе имеем картинку ОС в разрезе со всеми ее внутренностями:
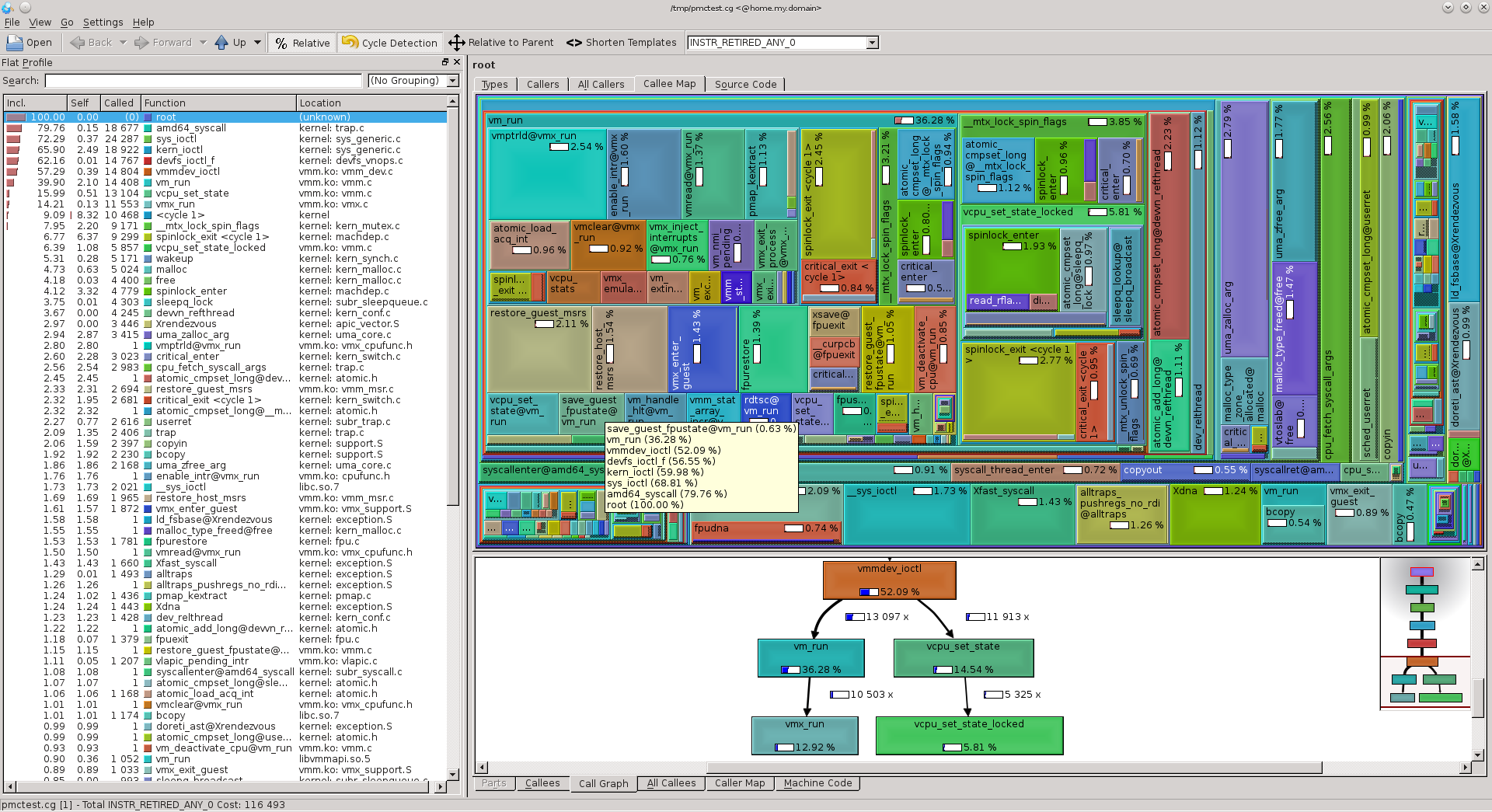
которая говорит сама за себя.
Тем не менее, в качестве эпилога, хотелось бы сказать, что поскольку гипервизорные методы не противоречат и не мешают контейнерам и наоборот, оба варианта могут успешно сосуществовать на одной хост системе.
Одним их хороших, если не идеальных кандидатов на роль виртуализации можно привести, к примеру, сервисы авторизации, тикет-системы, LDAP/Active Directory, почтовые релеи и тд - т.е. такие ресурсы, которые значительную часть своей жизни простаивают и при этом они не могут запускаться по каким-то причинам в хост-системе в качестве контейнера (например сервер под управлением Unix, а почтовый релей - на Microsoft Exchange).
Если же нагрузка на I/O высокая, или же у вас нет контр-доводов (live migration и тп) иметь систему, отличную от ОС хост-системы или другой архитектуры, предпочтения следует отдавать контейнеризации. Не смотря на рекламные слоганы о 99%-ой виртуальности инфраструктуры от менеджеров отдельных коммерческих продуктов виртуализации, вряд ли кто-то из них предпочтет получить виртуальный автомобиль взамен настоящего ;)